Biotoptypenkartierung
Biotoptypenkartierung
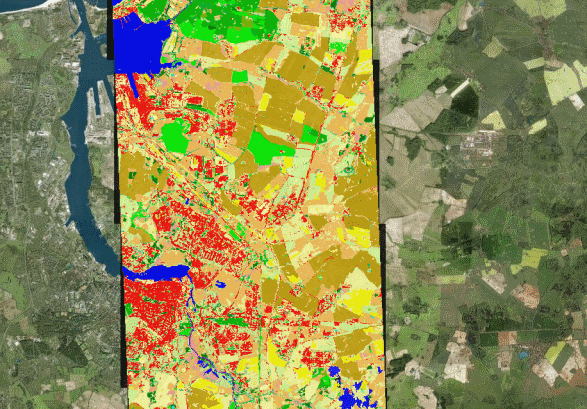
Die vorliegenden Daten unterteilen sich in zwei Datensätze: 1. einen Rasterdatensatz, welcher die vorläufige BNT-Klassifikation enthält und 2. einen Vektordatensatz, welchem die Biotop- und Landnutzungskartierung des Bundeslandes zu Grunde liegt. Die vorläufige BNT-Klassifikation des Rasterdatensatzes enthält vornehmlich die Hauptklassen der BNTK (Siedlung, Offener Boden, Wasser, Grünland, Landwirtschaftliche Nutzflächen und Baumvegetation) sowie einige Subklassen. Im Vektordatensatz dagegen sind alle Klassen der BNTK beinhaltet. Beide Datensätze liegen in UTM 33N/WGS84 vor.
Ziel:
Es wird angestrebt, die Biotoptypenkartierung durch die Klassifikation hoch auflösender Satellitendaten (RapidEye, TerraSAR-X) zu realisieren und zu automatisieren. Dabei ist von Interesse, inwieweit durch Interpretationen und automatische Klassifikation die Qualität (Klassentiefe) bestehender Produkte erreicht werden kann. Übergeordnetes Ziel ist die automatische Generierung einer Biotoptypenkarte, die möglichst die Klassentiefe bestehender Luftbildinterpretationen erreichen sollte. Das Verfahren soll zudem räumlich übertragbar sein. Im Rahmen der Untersuchungen zu Biotoptypen wird der Erfassung und Charakterisierung von Feldelementen besondere Aufmerksamkeit geschenkt.
Methodisches Vorgehen:
Für die bevorstehende Klassifikation wurden Merkmale definiert auf deren Basis die Klassifikation durchgeführt werden soll. Zunächst dienen die reinen spektralen Merkmale vor allem des Red-Edge- und NIR-Kanals, aufgrund ihrer hohen Sensitivität gegenüber Vegetation als Klassifikationsgrundlage. Desweiteren finden Indices wie der NDVI und der GEMI Anwendung. Der Normalized Difference Vegetation Index (NDVI) ist ein Ratio gebildet aus den Bändern im roten (pR) und nahen infraroten (pNIR) Wellenlängenbereich und besitzt eine hohe Sensitivität im Bereich der vitalen Vegetation. (3. Zwischenbericht)
Darüber hinaus wurde die Textur mittels einer Grey Level Co-occurrence Matrix (GLCM) berechnet. Hierbei wurden die Variance, Homogenity (auch Inverse Difference Moment), Contrast, Dissimilarity, Entropy, Second Moment und Correlation berechnet. Die Analyse zur Eignung der verschiedenen Texturmaße wurde anhand von sieben Klassen (Wasser, Grünland, Magerrasen, Baumgruppen und Hecken, Wälder und Forsten, Acker und Sonderstandorte und Siedlung durchgeführt. Diese Klassen entsprechen der Vorgabe der Biotop- und Landnutzungskartierungen des Landes Sachsen. Die Eignung der Merkmale wurde anhand der Trennbarkeit der Klassen evaluiert. Hierzu wurde die Bhattacharyya Distance verwendet. Auch bei dieser Auswertung zeigten sich die besten Trennbarkeiten anhand der Vegetationsindices und den drei schon genannten Texturmaßen (4. Zwischenbericht)
Die Klassifikation basiert auf einer Segmentierung in 3 Ebenen. Die erste Ebene beinhaltet eine sehr feine Segmentierung auf deren Basis z.B. die Trennung zwischen Laub- und Nadelwald stattfindet. Des Weiteren wird diese Ebene genutzt, um aus verschiedenen Klassen dieser ersten Ebene z.B. kleinen Wasserflächen und Grünlandflächen, Klassen auf der zweiten Ebene zu definieren. Wenn ein Objekt der zweiten Ebene einen bestimmten Anteil von kleinen Wasserflächen und Grünland in der ersten Segmentierungsebene besitzt, wird diesem Objekt die Klasse „Feuchtgrünland“ zugewiesen. Die zweite Ebene enthält somit naturnahe Objekte, welche sich aus den Objekten der ersten Segmentierungsebene zusammensetzten. Auf dieser Ebene findet der Großteil der Klassifikation statt. Als erster Schritt wird zwischen Vegetation und Nicht-Vegetation anhand von Vegetationsindices unterschieden. Auf Basis dieser beiden Klassen werden dann weitere Klassen definiert. Die Vegetation wird weiter unterteilt in 1. Baumvegetation, abgeleitet anhand eines Texturmaßes und spektraler Eigenschaften, 2. Grünland, abgeleitet anhand der SAR-Intensität und dem RedEdge-Kanal und 3. landwirtschaftlichen Nutzflächen, welche hauptsächlich anhand der Fläche der übrigen Vegetationsobjekte zugewiesen werden. Die dritte Segmentierungsebene beinhaltet die Objektgrenzen der Biotop- und Landnutzungskartierung (BNTK). Diese Ebene war gedacht um eine Validierung der Ergebnisse durchzuführen. Anhand der BNTK wurden Objekte als Referenz definiert und zusammen mit dem Klassifikationsergebnis in einer Genauigkeitsanalyse verwendet. (5. Zwischenbericht)
Weitere Informationen:
Die vorliegenden Daten unterteilen sich in zwei Datensätze: 1. einen Rasterdatensatz, welcher die vorläufige BNT-Klassifikation enthält und 2. einen Vektordatensatz, welchem die Biotop- und Landnutzungskartierung des Bundeslandes zu Grunde liegt. Die vorläufige BNT-Klassifikation des Rasterdatensatzes enthält vornehmlich die Hauptklassen der BNTK (Siedlung, Offener Boden, Wasser, Grünland, Landwirtschaftliche Nutzflächen und Baumvegetation) sowie einige Subklassen. Im Vektordatensatz dagegen sind alle Klassen der BNTK beinhaltet. Beide Datensätze liegen in UTM 33N/WGS84 vor.
OGC-konforme Datendienste:
- WMS GetMap: Biotops Classification (WMS)
- WCS DescribeCoverage: Biotops Classification (WCS)
Metadaten nach ISO-Standard:
Kontaktdaten:
FSU Jena
Marcus Bindel
Position: Ph.D. candidate
Telefon:
Telefax:
EMail: marcus.bindel@uni-jena.de
Anschrift:
Loebdergraben 32
07749 Jena